
In today’s workplace, access to information is crucial. From knowing the location of your office parking to configuring a server for specific applications, employees rely on quick and efficient access to accurate information. Yet, locating information in extensive knowledge bases can be challenging, often requiring time-consuming searches.
Using AI and LLM Chatbots
Recent advancements in AI, especially in natural language processing models like ChatGPT, have transformed information retrieval. Traditionally, people searched for information by visiting specific websites or using search engines like Google. Now, large language model (LLM) chatbots can answer many questions directly. However, these models are limited to general knowledge and lack access to domain-specific, internal documentation—keeping confidential information, like server passwords, secure.
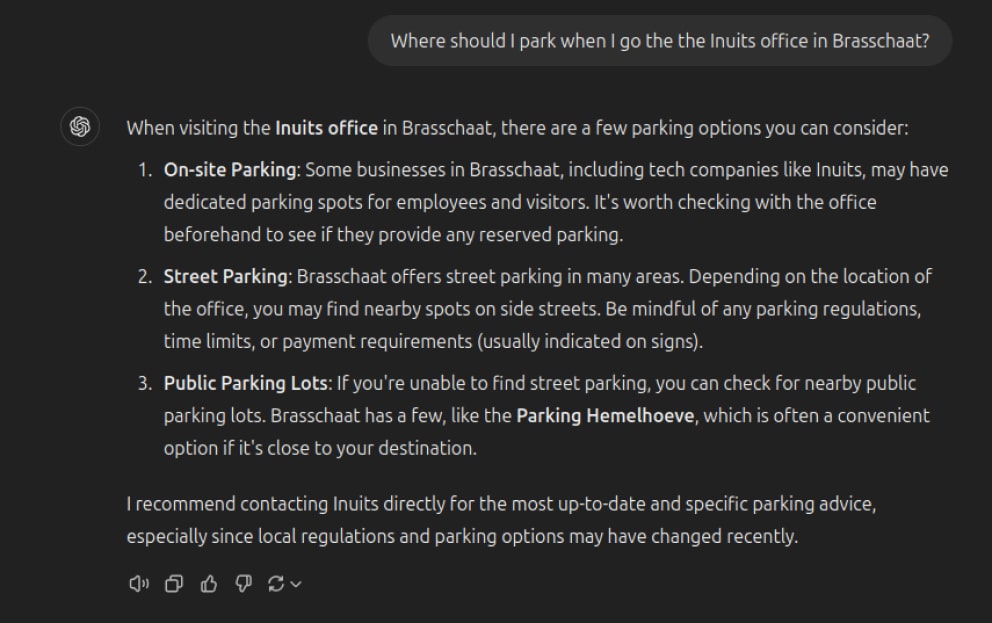
The Challenge of Domain-Specific Knowledge in AI
When it comes to specialized questions about a company’s unique documentation, LLMs may fall short. While they are excellent at handling general queries, they often cannot provide accurate answers to specific, internal questions. There are two main ways of solving this:
- Model Fine-Tuning: Training an AI model with company-specific data can improve its response accuracy for internal queries. However, fine-tuning is resource-intensive, requiring both GPU power and data preparation.
- Retrieval-Augmented Generation (RAG): RAG is a more scalable, cost-effective solution that combines AI capabilities to retrieve and deliver relevant answers using the company’s documentation.
What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) is a powerful AI technique that improves information retrieval by combining advanced search capabilities with the natural language generation abilities of language models.
In essence, RAG uses a dual approach: it retrieves relevant content from large document collections and then generates user-friendly responses based on this information. RAG combines semantic search and language models to improve information retrieval and relevance.
-
Semantic Embeddings: Using a compact AI model, RAG encodes company documentation into vector representations (embeddings) that capture semantic meaning. These vectors are stored in an index, enabling highly relevant document retrieval. During a search, user queries are also embedded, allowing the model to identify semantically similar documents, enhancing accuracy and relevance.
-
Augmenting Responses with LLMs: Pretrained language models, such as LLaMA or custom LLMs, can be used to summarize or extract key information from retrieved documents. By leveraging a self-hosted AI model, companies can securely use their documentation without risking data exposure to third-party services. This combined approach ensures the AI chatbot delivers accurate answers, drawing on internal documents for context.
By implementing RAG, companies can streamline access to information. Instead of sifting through extensive documents, employees receive relevant, summarized responses to their queries.
Tools and Technologies for RAG Implementation
To build a reliable RAG (Retrieval-Augmented Generation) system for Inuits’ documentation, we picked a set of tools to keep things fast, clear, and efficient. Here’s a rundown of what we used and why:
Frameworks
We went with LlamaIndex to set up our RAG pipeline since it easily manages document indexing and retrieval. We considered other frameworks like RAGFlow and Haystack but found LlamaIndex to be the best fit. LlamaIndex also offers flexible storage options, from storing in memory as JSON files to connecting with external databases.
Storage Solutions
For storing vector embeddings (the representations of our documents), we chose Redis because it’s fast and ideal for real-time use. Plus, if we need to expand, OpenSearch also works well with LlamaIndex for vector storage.
Tracking and Monitoring
We use MLflow to keep track of every step in the RAG process. This tool helps us see what’s happening in each stage and lets us track changes to prompts, so we know exactly what adjustments improve our results.
Model Backends
After testing a few options like transformers, llama.cpp, and vLLM, we landed on sentence-transformers for creating embeddings and LocalAI (using llama.cpp) for processing the language model. This setup worked best for our needs in terms of speed and accuracy.
User Interface
To make the system easy to use, we built a chatbot interface with Gradio. It’s a quick way to set up a simple, interactive chatbot, and it’s also widely used by AI hubs like Hugging Face.
Together, these tools support a reliable RAG pipeline, making it easier for Inuits employees to access documentation quickly, securely, and efficiently through a conversational AI interface.
Alternative Use Cases for RAG
RAG’s flexibility makes it valuable for many scenarios beyond internal documentation searches. Here are a few ways RAG can be applied effectively:
-
Customer Support: RAG can help support teams find quick answers to customer questions. It can power chatbots to handle common questions, saving support agents time and helping customers get answers faster.
-
Sales and Marketing: Sales teams can use RAG to pull up product info, case studies, or notes from past client meetings instantly. Marketing teams can quickly find insights on trends or competitors, helping them make decisions without digging through files.
-
Healthcare: Doctors and healthcare workers can use RAG to quickly look up medical records, guidelines, or research, giving them the info they need without wasting time searching, which is especially helpful in urgent situations.
-
Legal Work: Lawyers and compliance teams can use RAG to find relevant parts of case files, regulations, or policies, making research faster and helping them stay up-to-date with less effort.
-
Project Management: RAG can make it easy for teams to access project updates, timelines, or deliverables in one place. This way, team members stay on the same page without needing frequent status meetings.
Conclusion
In today’s workplace, RAG technology is transforming how we access and use information. By combining advanced search and language models, RAG provides fast, relevant answers, saving time and increasing productivity.
Whether in documentation access, customer support, or specialized fields like healthcare and legal, RAG offers a smarter, more efficient way to retrieve information. As AI advances, RAG’s potential will grow, making it an invaluable tool for modern, information-driven workplaces.


